ML Pipelines for Particle Tracking
Follow the tutorial in Quickstart to get up and running quickly with a toy model.
The Front Door
Assuming you've installed the Exatrkx tracking library and tried the Quickstart, then welcome. The aim of this repository is to both be a place to demonstrate our published results and pipelines, and also to show new developments in our work. To that end, various projects (i.e. physics use-cases) are given as templates in the Pipelines directory. To see a frozen reproduction of the pipeline used in our paper, go to Pipelines/TrackML_Example. A relatively frozen example of tracking on the ATLAS ITk detector is given in Pipelines/ITk_Example. Development code is available in Pipelines/Common_Tracking_Example, which is named due to many of the functions working across both detectors.
This page gives some outlines and justifications of the choice of the repository's organisation. The Models page defines the models used in track reconstruction. The Tools page describes the various stand-alone functions and concepts that are available in the library and could be useful across models. Performance is where metrics are defined, as well as tracking benchmarks.
How do Pipelines work?
The aim of our pipeline structure is to abstract out as much repetitive code as possible. A pipeline is defined by a YAML config file, which only requires three inputs: The location of your model definitions model_library, the location to save/load your artifacts artifact_library, and the stages of the pipeline stage_list. An example stage list is
- {set: GNN, name: SliceCheckpointedResAGNN, config: train_gnn.yaml}
The set key defines the type of ML model (to help avoid naming ambiguity), the name key is the class of the model, and the config key is the file specifying your choice of hyperparameters, directories, callbacks and so on. And that's it!
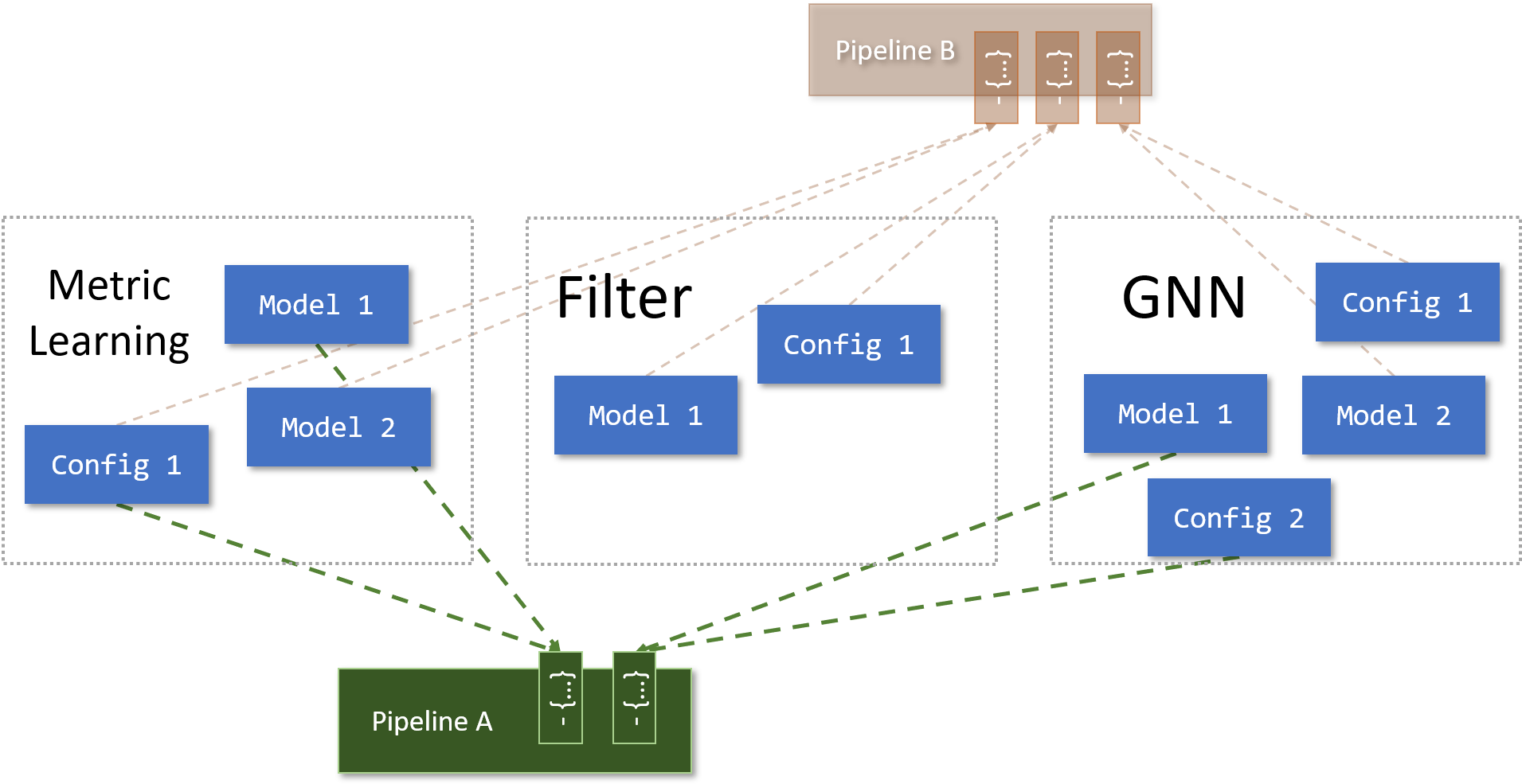
Why this choice of abstraction?
I found that my two forms of R&D fell into breadth and depth. Much of the time, I would play at length with hyperparameters and model definitions, in which case I want that all to live in one place: The model's config file. Thus the pipeline config can remain untouched if we have one for each choice of (model, config) , or only changed occasionally if we choose to have only one. At other times, development would require a series of models, where successive results depend on hyperparameter choices earlier in the chain. Then I can play with the higher level pipeline config and try difference (model, config) stages, while the whole chain of hyperparameters is committed to each step via a logging platform (Weights & Biases in my case).
Pytorch Lightning
This repository uses Pytorch Lightning, which allows us to encapsulate all training and model logic into a module object. This module is what is being specified by the pipeline config, with name. Combined with callbacks in the model config file, all pipeline logic is contained in each module. A callback object integrates with the module and knows about telemetry and post-processing steps. Rather than a monolithic function that passes data through the pipeline (whereby mistakes could be made), the pipeline asks each model how it should be treated, and then acts with the model's own methods.